Table of Contents
- Introduction
- The Surprising Simplicity of RAG
- Why This "Janky" Approach Actually Works
- When Simple Concatenation Falls Short
- The Beauty of Artificial Intelligence
Introduction
After years of working in backend development, I recently dove back into the ML and LLM space to build Cravings, a lightweight RAG (Retrieval-Augmented Generation) chatbot that suggests recipes based on how you're feeling. Using Google Gemini API's free-tier Flash models, a Qdrant vector database hosted on GCP, FastEmbed for local text embedding, and a FastAPI backend, I was expecting something... more sophisticated under the hood. What I found instead was surprisingly simple: the retrieved data was just concatenated strings fed directly to the LLM. No fancy JSON protocols, no structured schemas, just plain text mashed together and handed off to the model.
This revelation was both jarring and fascinating. Coming from a world where APIs communicate through carefully structured JSON payloads and databases return normalized data with clear schemas, seeing RAG systems work with what essentially amounts to "copy-paste" operations felt primitive. Yet, these systems are powering some of the most impressive AI applications we see today How can something so seemingly crude be so effective?
The Surprising Simplicity of RAG
At its core, RAG works by retrieving relevant information from external sources and concatenating it as context with the original input prompt before feeding it to the text generator When I query Cravings about comfort food recipes, the system retrieves similar recipe chunks from the vector database, literally strings them together with some basic separators, and presents this concatenated mess to Gemini. No parsing, no structured data transformation—just raw text concatenation. 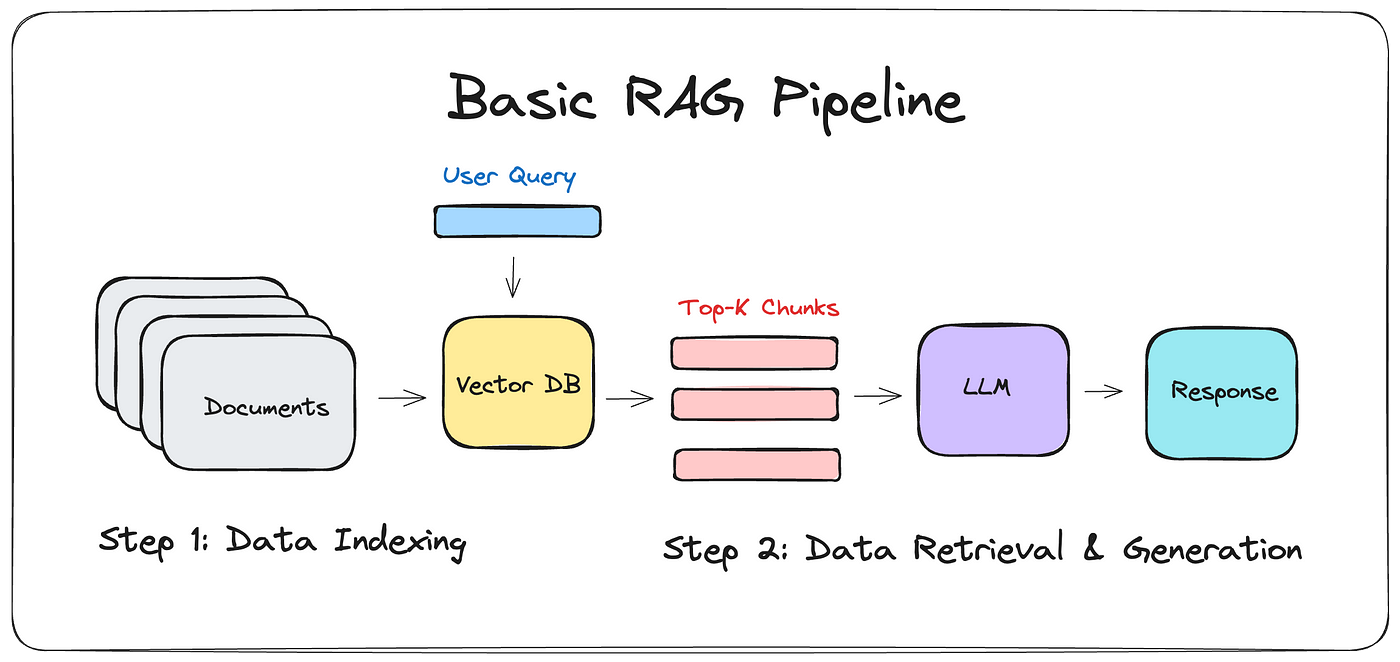
This approach initially struck me as inefficient. In traditional software systems, we spend enormous effort optimizing data structures, creating clean interfaces, and ensuring type safety. Yet here was a system that deliberately throws structured data out the window and relies on the LLM to make sense of unstructured text blobs.
Why This "Janky" Approach Actually Works
The effectiveness of concatenated strings in RAG systems stems from how Large Language Models process information. Unlike traditional programs that require explicit data structures and protocols, LLMs are fundamentally designed to understand and generate human language—which is inherently unstructured. They excel at extracting meaning from context, regardless of how that context is formatted.
The Power of Attention Mechanisms
After digging, I found that the answer lies in the attention mechanism thats present in the transformer-based LLMs. When an LLM processes concatenated text, it doesn't just read it sequentially like a traditional parser. Instead, it uses self-attention to dynamically focus on different parts of the input, assigning varying weights to each piece of information based on its relevance to the current task.
For example, when processing a prompt like "Context: Recipe for chocolate chip cookies... User Question: How do I make cookies chewy?", the attention mechanism allows the model to automatically identify and prioritize the relevant recipe steps related to texture while ignoring irrelevant details. This dynamic weighting happens at the token level, enabling the model to extract meaningful relationships even from seemingly messy concatenated text.
LLMs as Universal Parsers
What makes this particularly elegant is that LLMs function as universal parsers. They've been trained on massive amounts of text data that includes everything from structured JSON to rambling forum posts, technical documentation to poetry. This training gives them an inherent ability to extract signal from noise, regardless of the input format.
In essence, the "jankiness" of concatenated strings becomes irrelevant because the LLM has learned to parse human language in all its messy, unstructured glory. The model's robustness to noisy input is actually a feature, not a bug.
When Simple Concatenation Falls Short
While concatenated strings work remarkably well for many RAG applications, they're not without limitations. Research shows that LLMs can struggle with deeply nested or highly structured data when presented as plain text. Complex relationships between data points may be lost in translation, and the model's ability to maintain accuracy degrades when dealing with very long concatenated contexts.
Additionally, the lack of explicit structure can make it difficult to trace how the model arrived at its conclusions, which is problematic for applications requiring explainability. Some advanced RAG systems are beginning to experiment with structured prompting techniques and special tokens to provide better guidance to the LLM about how to interpret different sections of the concatenated context.
The Beauty of Artificial Intelligence
If it works, it ain't broke
What initially felt like a hack is actually a proof to the intelligence of these systems. The ability to extract meaning from unstructured input mirrors how humans process information. We don't require data to be perfectly formatted to understand it; we use context, pattern recognition, and prior knowledge to make sense of messy, real-world information.
RAG systems leverage this same capability. By feeding LLMs concatenated text that includes both the retrieved context and the user's question, we're essentially recreating the human experience of consulting multiple sources to answer a question. The "jankiness" disappears when we realize that the LLM's training has prepared it to handle exactly this type of unstructured input.